


Alguna vez se han puesto a pensar ¿Qué porcentaje del parque vehicular no son autos particulares sino que ofrecen algún servicio de transporte?. Para poner un ejemplo de la importancia de esta clase de servicios, según datos del INEGI (2020) solamente el servicio de mensajería y paquetería esta presente en 743 de las 822 actividades económicas del país, poco más del 90%, lo que significa que apoya a casi todos los sectores de la economía.

De igual manera como podemos ver en la imagen, existen otra clase de servicios de transporte más importantes como el autotransporte de carga. El autotransporte de carga es la actividad dedicada a transportar productos o mercancías de cualquier tipo, pudiendo requerir para su transportación equipo especializado o no. Este tipo de transporte suele ser utilizado en la cadena de suministro, la cual se puede definir como el conjunto de pasos y elementos que le permiten a las empresas adquirir los recursos para producir o manufacturar un producto. De igual manera el autotransporte se usa en lo que se conoce dentro del área de logística como distribución de última milla, que es la etapa de entrega de un producto desde un centro de distribución (CEDIS) a el cliente final.
** Te podría interesar: «Categorizando las zonas con choques y siniestro en Nuevo León»

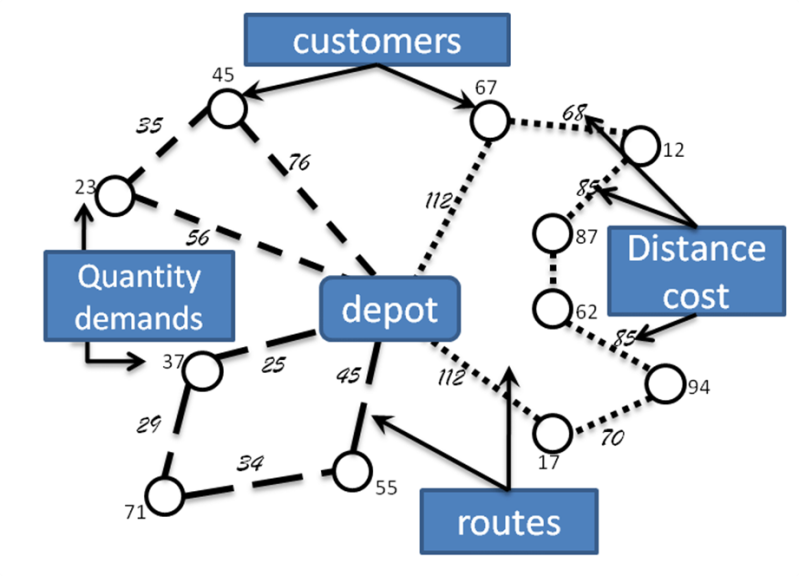
Estos dos tipos de transporte tienen varias cosas en común, pero una de ellas es la necesidad de generar rutas de viaje que les permitan optimizar uno o más atributos, por ejemplo: maximizar el número de clientes atendidos durante un turno o minimizar las emisiones de carbono de toda la ruta. Este tipo de problemas en investigación de operaciones se conoce como problema de ruteo de vehículos (VRP – vehicule routing problem).
El VRP es un problema de optimización combinatoria descrito por primera vez en 1959 por el matemático Dantzing. El objetivo del problema es encontrar las rutas optimas de vehículos que parten de un depósito, atienden a cada cliente y después regresan al depósito.

A pesar de ser un problema común en la mayoría de las empresas, resolver un VRP es computacionalmente costoso y se categoriza como NP-Hard porque en la vida real puede involucrar restricciones que introducen una complejidad significativa al problema, algunas de estas características se enlistan a continuación:
- Ventanas de tiempo: Los clientes tienen restricciones de tiempo para satisfacer su demanda
- Tiempos de viaje dependientes del horario: Consideran factores que cambian con respecto al horario como el tráfico.
- Múltiples depósitos: En los VRPs clásicos hay un solo depósito, en este caso se consideran varios.
- Flotas heterogéneas: Los vehículos no tienen las mismas características.
- Rutas con recolección y entrega: Para algunos clientes se deja algún producto y en otros se recolecta o ambos.
- Los vehículos no regresan al depósito de origen: No regresan al mismo depósito del que partieron forzosamente. Aplica en casos como en la renta de vehículos.
- Algunas variables son aleatorias y se pueden encontrar dentro de un rango de probabilidad.
- Multiobjetivo: Se pueden considerar varios objetivo a maximizar o minimizar

Formas de resolverlo
Un VRP puede ser resuelto de varias formas. Mediante un método exacto como un modelo de optimización, un modelo de programación dinámica o programación por restricciones. De igual manera se puede resolver mediante un algoritmo de aproximación de soluciones como una metaheurística.

Modelo de optimización
A continuación se describe un modelo de optimización para el VRP clásico, para el que se hacen varias asunciones:
- El depósito tiene demanda cero
- Cada ubicación o cliente es atendido solamente por un vehículo
- La demanda de cada cliente es indivisible
- El vehículo no excede su capacidad de carga
- El vehículo inicia y termina en un depósito
- La demanda, distancias y costos de entrega de los clientes son conocidos
El modelo matemático se muestra en la siguiente imagen

En este modelo cij representa el costo de ir del nodo i al nodo j. La variable binaria xij tomara el valor de 1 si se usa el arco para ir del nodo i al nodo j, 0 en otro caso. K es el número de vehículos disponibles y r(S) representa el número mínimo de vehículos necesarios para atender a todos los clientes.
La restricción 1 y 2 establecen que solo un arco entra y solo un arco sale de cada vértice. Las restricciones 3 y 4 establecen que el número de vehículos que salen del depósito es el mismo que regresa. La restricción 5 son las restricciones de corte la cual establece que todas las rutas deben de estar conectadas y que la ruta no debe de exceder la capacidad del vehículo. La restricción 6 es es una restricción de integralidad de las variables.
** Te puede interesar nuestra participación en HACK MTY con un reto de choques y siniestros con alumnos y alumnas del TEC de MTY
Este tipo de modelos pueden ser programados en distintos lenguajes de programación como Python, C++, Java, etc., y suelen usar software especializados como GUROBI, CPLEX.
Métodos de aproximación
Otra forma de resolver un VRP es mediante la implementación de metaheurísticas. Una metaheurística es un algoritmo capaz de generar soluciones de buena calidad para un problema en especifico pero sin asegurar optimalidad. Generalmente son usadas como alternativas a los métodos exactos debido a que tienen la capacidad de resolver problemas complejos como un VRP con instancias grandes, ofreciendo soluciones de buena calidad en un tiempo computacional usualmente menor a un método exacto. Algunos ejemplos de dichos algoritmos son:
- Tabu search
- Algoritmos genéticos
- GRASP
- VNS
- Simulated Anealing
- entre otros…
Al igual que con los modelos de optimización, estos algoritmos pueden programarse con distintos lenguajes de programación como Python, C++, Java, etc.
Keep it weird
Ligas de interés:
- https://www.inegi.org.mx/contenidos/productos/prod_serv/contenidos/espanol/bvinegi/productos/nueva_estruc/889463903727.pdf
- https://www.inegi.org.mx/contenidos/productos/prod_serv/contenidos/espanol/bvinegi/productos/nueva_estruc/889463903994.pdf
- https://unisolutionsnews.wordpress.com/2016/08/22/que-es-el-vrp-y-cuales-son-sus-variantes/
- https://en.wikipedia.org/wiki/Vehicle_routing_problem








